How to Determine Which Clustering Method to Use
It is also a bit naive in its approach. N is the number of samples within the data set C is the center of a cluster.
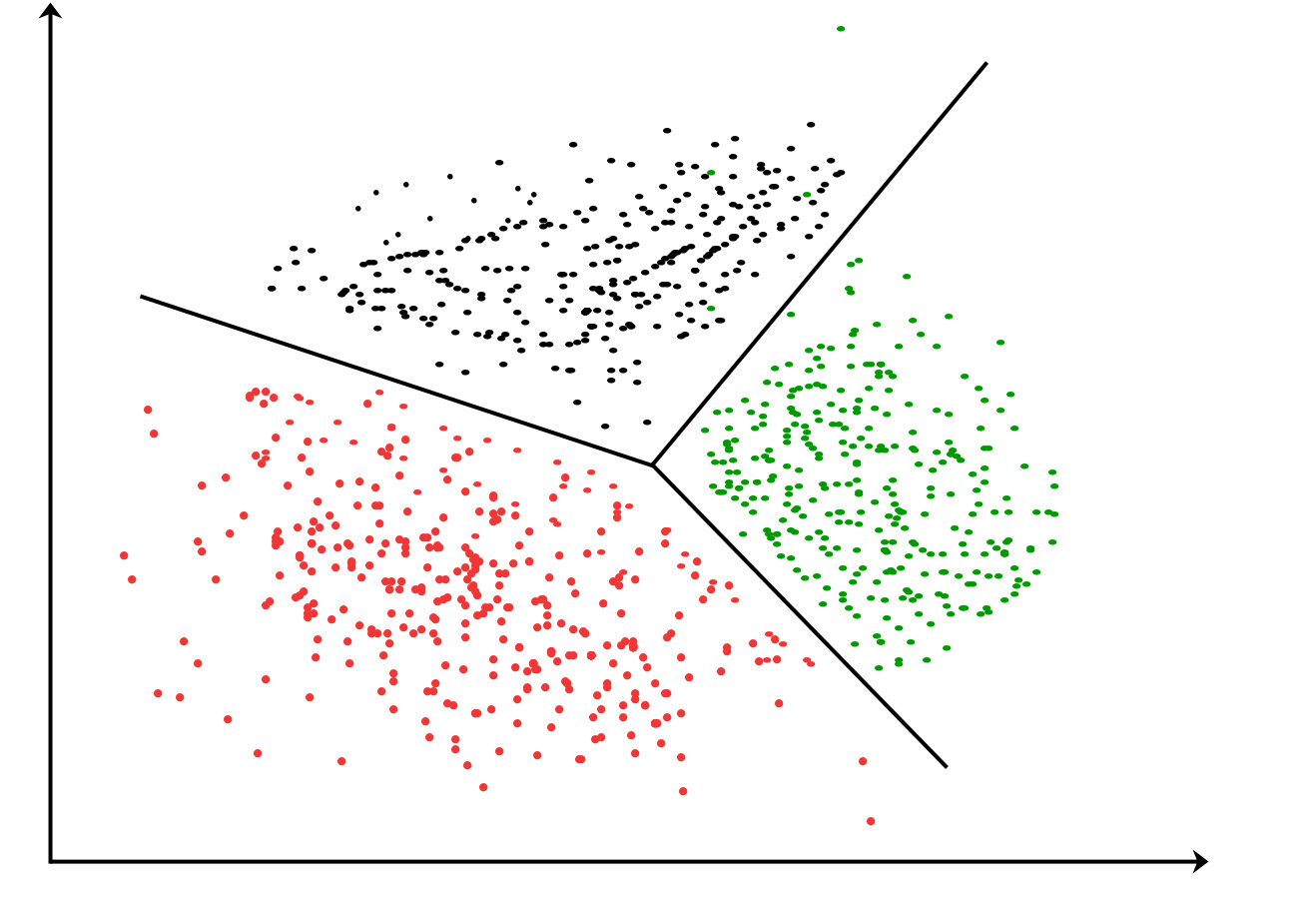
Clustering In Machine Learning Geeksforgeeks
Distance measures and similarity measures.

. Sometimes one choice might influence the other but there are many possible combinations of methods. Determining the optimal number of clusters in a data set is a fundamental issue in partitioning clustering such as k-means clustering which requires the user to specify the number of clusters k to be generated. Also the mbcFit and mbcScore actions in SAS Viya perform model based clustering using mixtures of multivariate Gaussians.
Pick the value of k. More precisely if one plots the percentage of variance explained by the clusters against the number of clusters the first clusters will add much. What method do we use to find the optimal number of clusters range for K-means clustering method.
First we must decide how many clusters wed like to identify in the data. So you could say there are 7 4 or 3 potential clusters. In turn the average characteristics of a group serve us to characterize all individuals in the corresponding cluster.
Another method is to look at the increase in SSE or whatever clustering coefficient is used remember in Wards method it is SSE at each subsequent stage of clustering. Since clustering is the grouping of similar instancesobjects some sort of measure that can determine whether two objects are similar or dissimilar is required. For this reason k-means is considered as a supervised technique while hierarchical.
Since we dont know beforehand which method will produce the best clusters we can write a short function to perform hierarchical clustering using several different methods. We want to determine a way to compute the distance between each of these points. Unfortunately there is no definitive answer to this question.
Elbow Method is an empirical method to find the optimal number of clusters for a dataset. In this blog I will go a bit more in detail about the K-means method and explain how we can calculate the distance between centroid and data points to form a cluster. We can randomly choose Read More Steps to calculate centroids in cluster using K-means.
Note that this function calculates the agglomerative coefficient of each method which is metric. Here each data point is a cluster of its own. How Does Hierarchical Clustering Work.
Basic version of HAC algorithm is one generic. Up to 10 cash back This article first present a set of index system which is suitable for profile control and water shut-off then uses ISODATA clustering analysis method to determine the existence of thief zone and levels of thief zone in different wells to provide a theoretical basis for determining which well should be tuned profile. Find the average distance of each point in a cluster to its centroid and represent it in a plot.
We will use the elbow method which plots the within-cluster-sum-of-squares WCSS versus the. In practice we use the following steps to perform K-means clustering. Repeat until data points stay in the same cluster.
The first is generally used when the number of classes is fixed in advance while the second is generally used for an unknown number of classes and helps to determine this optimal number. It can be seen here as well there is a big change from 7 to 6 4 to 3 and 3 to 2. Choose a value for K.
The Inertia or within cluster of sum of squares value gives an indication of how coherent the different clusters are. Next lets define the inputs we will use for our K-means clustering algorithm. X i i1N points in R p each coordinate is a feature for the clustering Clustering method.
The optimal number of clusters is somehow subjective and depends on the method used for measuring. Many clustering methods use distance measures to determine the similarity. The two most common types of classification are.
There are two main type of measures used to estimate this relation. The Elbow Method The Elbow Method This is probably the most well-known method for determining the optimal number of clusters. Lets use age and spending score.
Lets consider that we have a few points on a 2D plane with x-y coordinates. One should choose a number of clusters so that adding another cluster doesnt give much better modeling of the data. So the Inertia simply computes the squared distance of each.
Short reference about some linkage methods of hierarchical agglomerative cluster analysis HAC. X dfAge Spending Score 1-100copy The next thing we need to do is determine the number of clusters that we will use. To assign a new data point to an existing cluster you calculate how likely it is for the new data point to belong to each distribution.
The method to use to calculate dissimilarity between clusters. The elbow method looks at the percentage of explained variance as a function of the number of clusters. When using cluster analysis on a data set to group similar cases one needs to choose among a large number of clustering methods and measures of distance.
In this method we pick a range of candidate values of k then apply K-Means clustering using each of the values of k. Equation 1 shows the formula for computing the Inertia value. It amounts to updating at each step by the formula known as Lance-Williams formula the proximities between the emergent merged of two cluster and all the other clusters including singleton.
Consider the below data set which has the values of the data points on a particular graph. Clustering by using the GMM procedure in SAS Viya. For this we try to find the shortest distance between any two data points to form a cluster.
An individual is characterized by its membership to a certain cluster. We can take the output of a clustering method that is take the clustering memberships of individuals and use that information in a PCA plot. Hierarchical with given choices of metric and link function or k-means with given choice of metric With method and K clusters we obtain a partition of the points.
Methods to determine the number of clusters in a data set Data set. Often we have to simply test several different values for K and analyze the results to see which number of clusters seems to make the most sense for a given problem.

Hierarchical Clustering Foundational Concepts And Example Of Agglomerative Clustering Machine Learning Algorithm Predictive Analytics
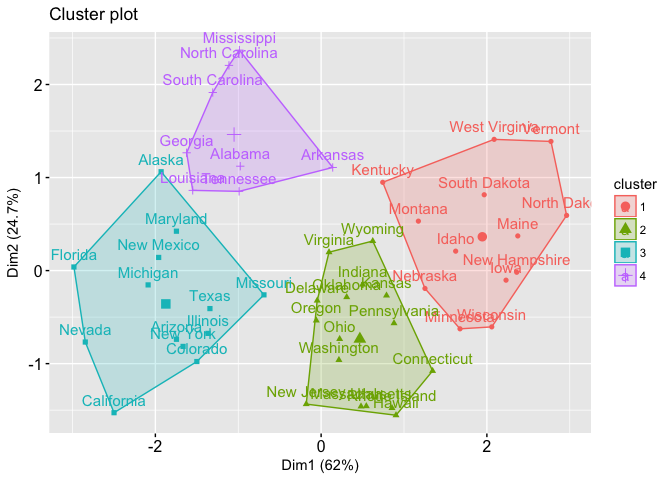
K Means Cluster Analysis Uc Business Analytics R Programming Guide

Exploring Clustering Algorithms Explanation And Use Cases Neptune Ai
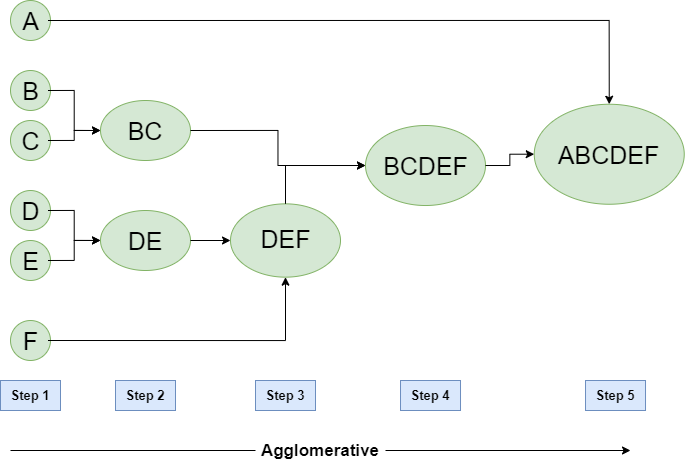
Hierarchical Clustering In Data Mining Geeksforgeeks
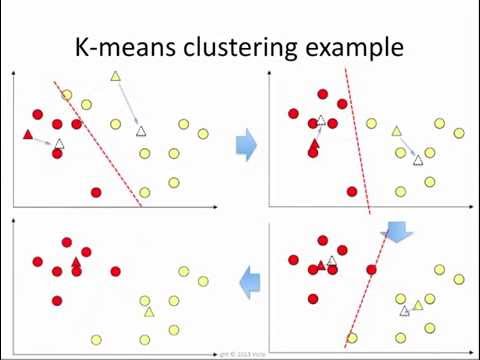
K Means Clustering How It Works Youtube
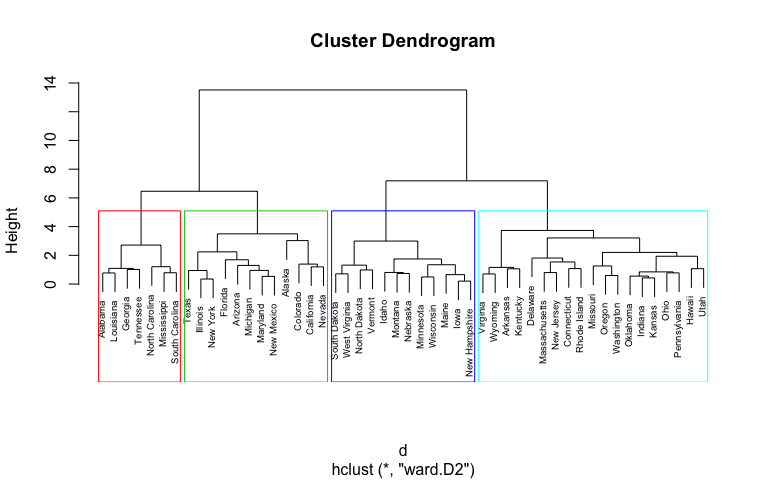
Hierarchical Cluster Analysis Uc Business Analytics R Programming Guide
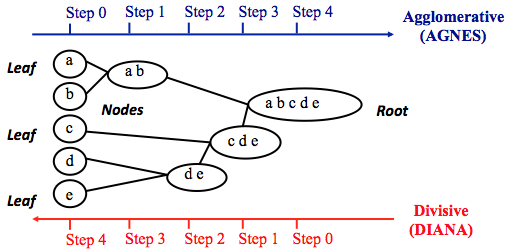
Hierarchical Cluster Analysis Uc Business Analytics R Programming Guide
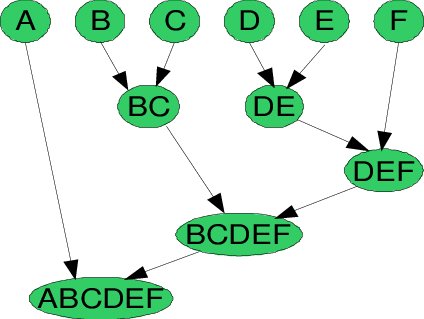
Understanding The Concept Of Hierarchical Clustering Technique By Chaitanya Reddy Patlolla Towards Data Science

Panel Data Analysis A Survey On Model Based Clustering Of Time Series Analysis Data Analysis Data
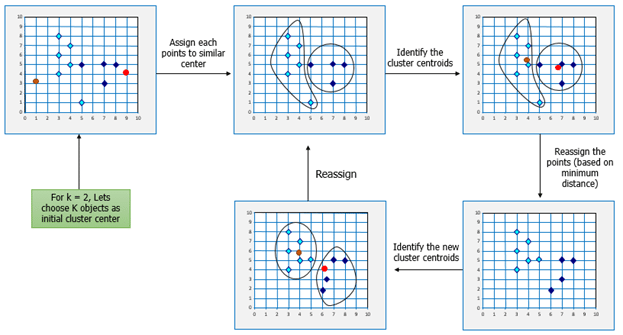
Understanding K Means Clustering With Examples Edureka

Danaleeds Com Dna Color Clustering Aka The Leeds Method Leeds Method Geneology
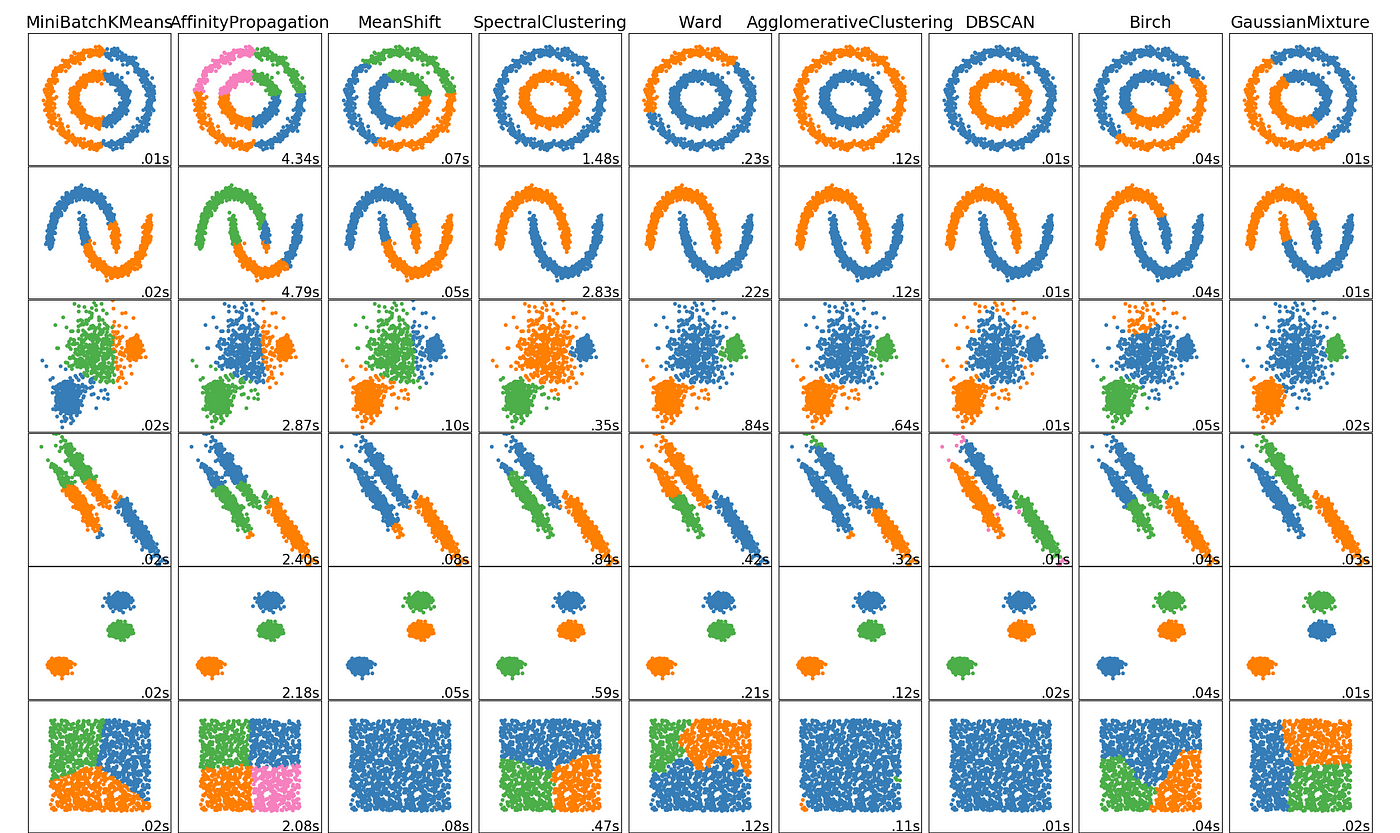
The 5 Clustering Algorithms Data Scientists Need To Know By George Seif Towards Data Science

How To Automatically Determine The Number Of Clusters In Your Data And More Data Science Cen Data Science Exploratory Data Analysis Collaborative Filtering

Clustering Algorithm An Overview Sciencedirect Topics
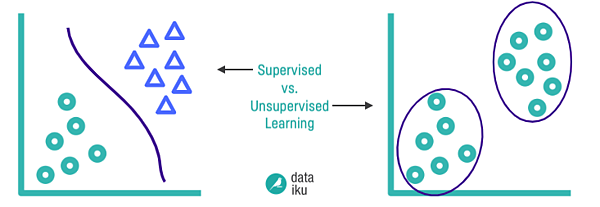
Clustering How It Works In Plain English
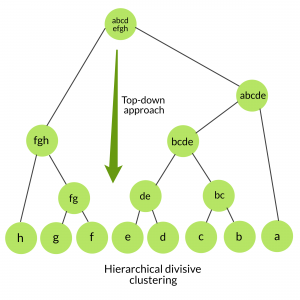
Ml Hierarchical Clustering Agglomerative And Divisive Clustering Geeksforgeeks
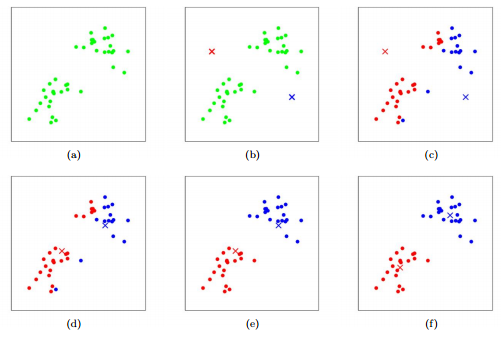
Cs221

Clustering Metrics Better Than The Elbow Method Data Patterns Marketing Goals Data Science
A Comprehensive Guide On Clustering And Its Different Methods Method Biomedical Predictive Analytics



Comments
Post a Comment